NLP Q&As Series - Part 1: Language Models and Transformer.
Intro
This is a series of short questions and answers about NLP, originally shared on my LinkedIn page.
Q1: What is a Language Model?
A language model serves as a probabilistic representation of one or more languages, determining the likelihood of a given sequence of words belonging to a particular language. Essentially, it answers the question:
What is the probability of this word sequence being part of the language? Consider two statements:
- “Mohammed studied business in college.”
- “college Mohammed business in studied.”
Statement 1 has a higher probability of being a valid English sentence compared to Statement 2.
Language models have evolved from statistical models, such as n-gram language models, to neural language models based on various types of recurrent neural networks. Presently, they predominantly rely on Transformers and are often referred to as Large Language Models (LLM).
Applications of language models are diverse, but a common thread is that any application generating a text sequence benefits from an LM. The LM guides the generation process by producing high-probability sequences. Examples of such applications include speech recognition, machine translation, and optical character/handwriting recognition.
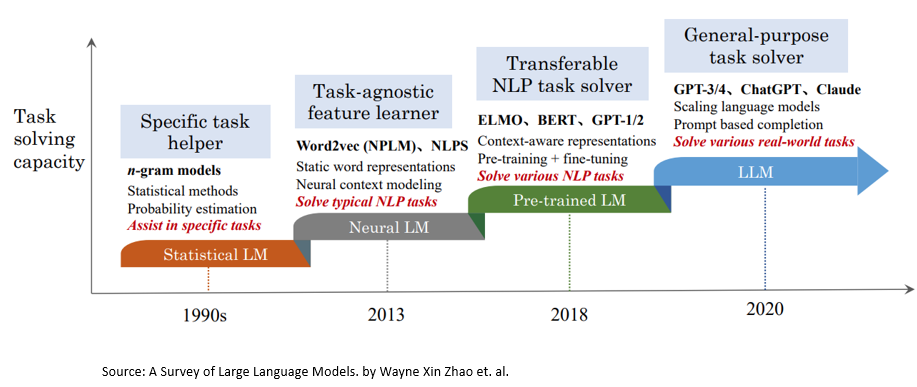
Source: A Survey of Large Language Models.
Source: A Survey of Large Language Models.
Q2: Describe the Transformer Architecture in a high level.
The Transformer model is a seq2seq, i.e. it processes input sequences and generates output sequences.
The journey of a sentence in the Transformer involves two main components: the Encoder and the Decoder.
Preprocessing Steps:
- Tokenization: The sentence is divided into tokens.
- Embeddings: Each token is transformed into a high-dimensional vector.
- Positional Encoding: Information about the token’s position in the sentence is added to its embeddings.
Encoder:
The Encoder consists of multiple (e.g., 6) layers, each mainly having:
- Multi-Head Attention: Tokens’ embeddings are passed to a neural network that updates them considering information from other tokens in the input.
- Feed-Forward: A neural network applied to each token’s embeddings separately.
Decoder:
The Decoder takes two inputs: the Encoder’s output and previously generated tokens (as embeddings). The model generates the output sequence one token at a time.
A Decoder also consists of multiple layers, each mainly having:
- Masked Multi Head Attention: For each generated token, updates its embeddings considering information from other tokens.
- Multi-Head Attention: For each generated token, updates its embeddings considering information from Encoder output.
- Feed-Forward: Utilizes a similar structure as in the Encoder.
Finally: The current output token is determined using a Linear Layer followed by a Softmax.
Note: This is a high-level description, some parts are left out, and some are oversimplified.
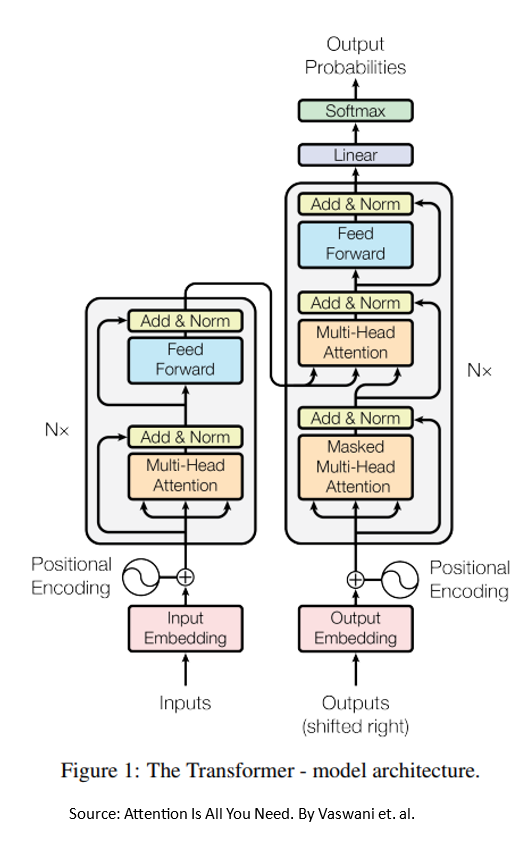
Source: Attention is All You Need.
Q3: What is Attention?
The concept of attention goes beyond its application in the Transformer, it is not exclusive to NLP models either. Attention refers to a mechanism by which a model directs its focus or attends to specific segments of the input aiming to enhance the output, or more precisely, to generate a more effective representation that contributes to better output.
The following is an explanation of how this is done in the Transformer model.
Each token is associated with three vectors: Query, Key, and Value (q, k, v).
When processing the i_th token, a dot product is performed between its query vector q_i and the key vectors of all tokens. Each dot product gives a numerical result that indicates the “compatibility” between the i_th token and all other tokens.
Previous results are then scaled and a Softmax is applied on them. The outcome is a set of attention weights—one for each token. These weights are now multiplied by the corresponding value vectors and the resulting vectors are added together.
So essentially, the output of the attention operation for the i_th token is a weighted sum of the value vectors of all tokens, the weights are calculated by a scaled dot product between the i_th query vector and the all key vectors.
Next Q&A: What is Self-Attention, Cross-Attention, Multi-head Attention, and Masked Attention?
Stay tuned.